Measurement of selectivity of top-layer neurons to images of Faces vs. images of Objects. The baseline pretrained Alexnet model (left) has randomly organized selectivity as expected. We see the Topographic VAE (middle) yeilds spatially dense clusters of neurons selective to images of faces, reminiscent of the ‘face patches’ observed in the primate cortex. The TVAE clusters are seen to be qualitatively similar to those produced by the supervised TDANN model of Lee et al. (2020) (right) without the need for class-labels during training.
We introduce a modification of the Topographic VAE, allowing it to be used in an online manner as a predictive model of the future. We observe that the Predictive Coding TVAE (PCTVAE) is able to learn more coherent sequence transformations (left) when compared with the original Topographic VAE (right).
Overview of the Topographic VAE with shifting temporal coherence. The combined color/rotation transformation in input space \(\tau_g\) becomes encoded as a \(\mathrm{Roll}\) within the equivariant capsule dimension. The model is thus able decode unseen sequence elements by encoding a partial sequence and rolling activations within the capsules. We see this completes a commutative diagram.
A matrix \(\mathbf{W}\) transforms data from \(\mathbf{X}\) to \(\mathbf{Z}\) space. The matrix \(\mathbf{R}\) is constrained to approximate the inverse of \(\mathbf{W}\) with a reconstruction loss \(||\mathbf{x} - \mathbf{\hat{x}}||^2\). The likelihood of the data is efficiently optimized with respect to both \(\mathbf{W}\) and \(\mathbf{R}\) by approximating the gradient of the log Jacobian determinant with the learned inverse.
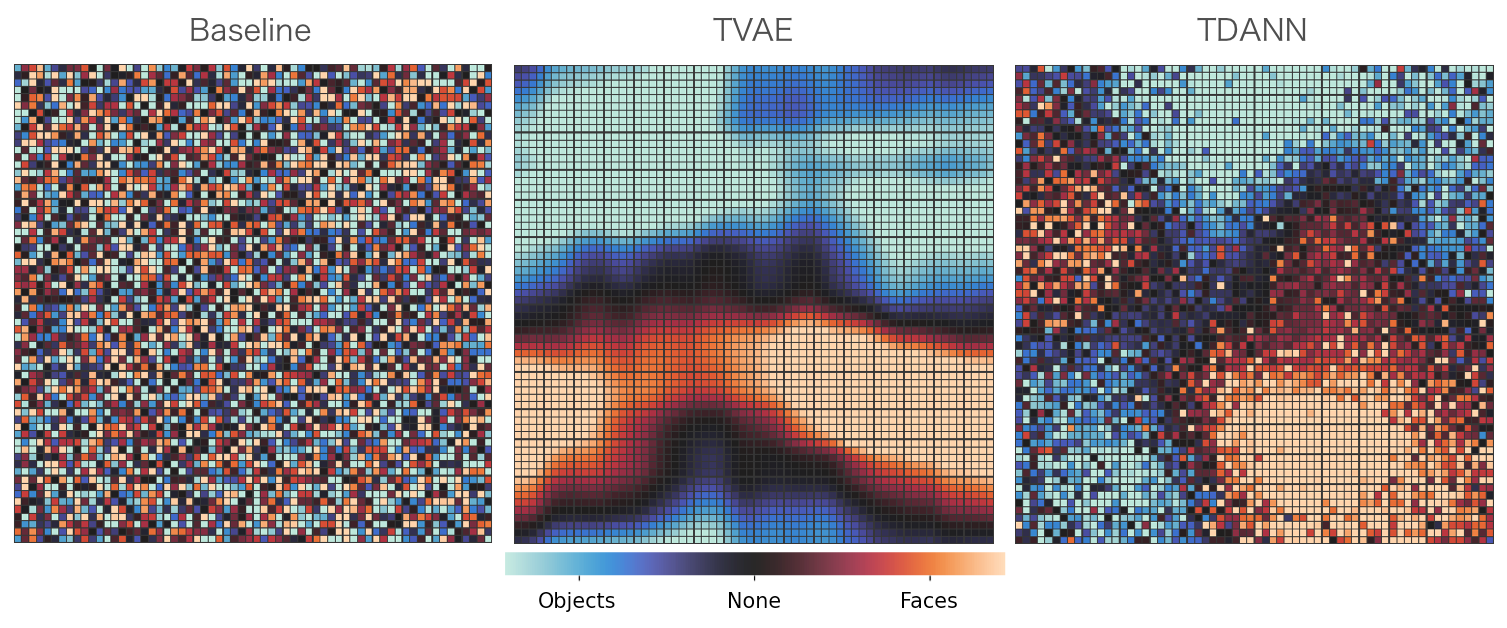 Measurement of selectivity of top-layer neurons to images of Faces vs. images of Objects. The baseline pretrained Alexnet model (left) has randomly organized selectivity as expected. We see the Topographic VAE (middle) yeilds spatially dense clusters of neurons selective to images of faces, reminiscent of the ‘face patches’ observed in the primate cortex. The TVAE clusters are seen to be qualitatively similar to those produced by the supervised TDANN model of Lee et al. (2020) (right) without the need for class-labels during training.
Measurement of selectivity of top-layer neurons to images of Faces vs. images of Objects. The baseline pretrained Alexnet model (left) has randomly organized selectivity as expected. We see the Topographic VAE (middle) yeilds spatially dense clusters of neurons selective to images of faces, reminiscent of the ‘face patches’ observed in the primate cortex. The TVAE clusters are seen to be qualitatively similar to those produced by the supervised TDANN model of Lee et al. (2020) (right) without the need for class-labels during training. We introduce a modification of the Topographic VAE, allowing it to be used in an online manner as a predictive model of the future. We observe that the Predictive Coding TVAE (PCTVAE) is able to learn more coherent sequence transformations (left) when compared with the original Topographic VAE (right).
We introduce a modification of the Topographic VAE, allowing it to be used in an online manner as a predictive model of the future. We observe that the Predictive Coding TVAE (PCTVAE) is able to learn more coherent sequence transformations (left) when compared with the original Topographic VAE (right).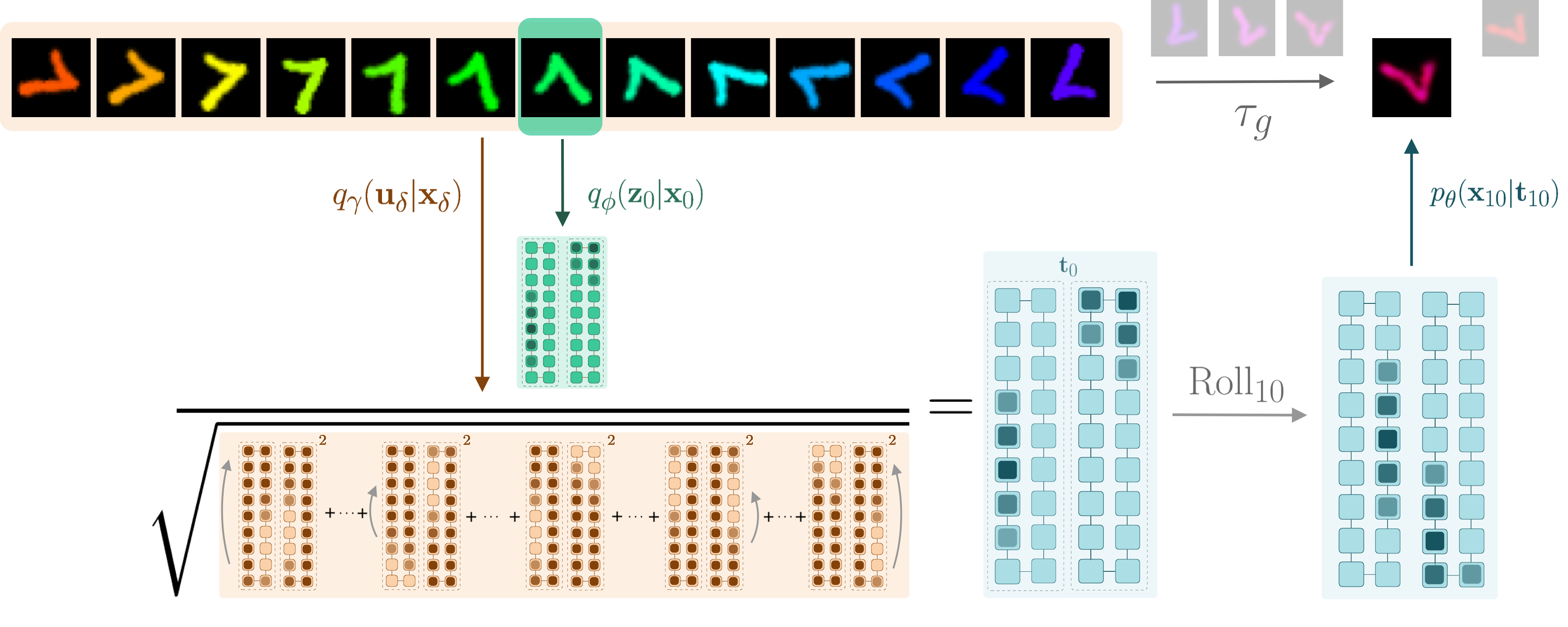 Overview of the Topographic VAE with shifting temporal coherence. The combined color/rotation transformation in input space \(\tau_g\) becomes encoded as a \(\mathrm{Roll}\) within the equivariant capsule dimension. The model is thus able decode unseen sequence elements by encoding a partial sequence and rolling activations within the capsules. We see this completes a commutative diagram.
Overview of the Topographic VAE with shifting temporal coherence. The combined color/rotation transformation in input space \(\tau_g\) becomes encoded as a \(\mathrm{Roll}\) within the equivariant capsule dimension. The model is thus able decode unseen sequence elements by encoding a partial sequence and rolling activations within the capsules. We see this completes a commutative diagram.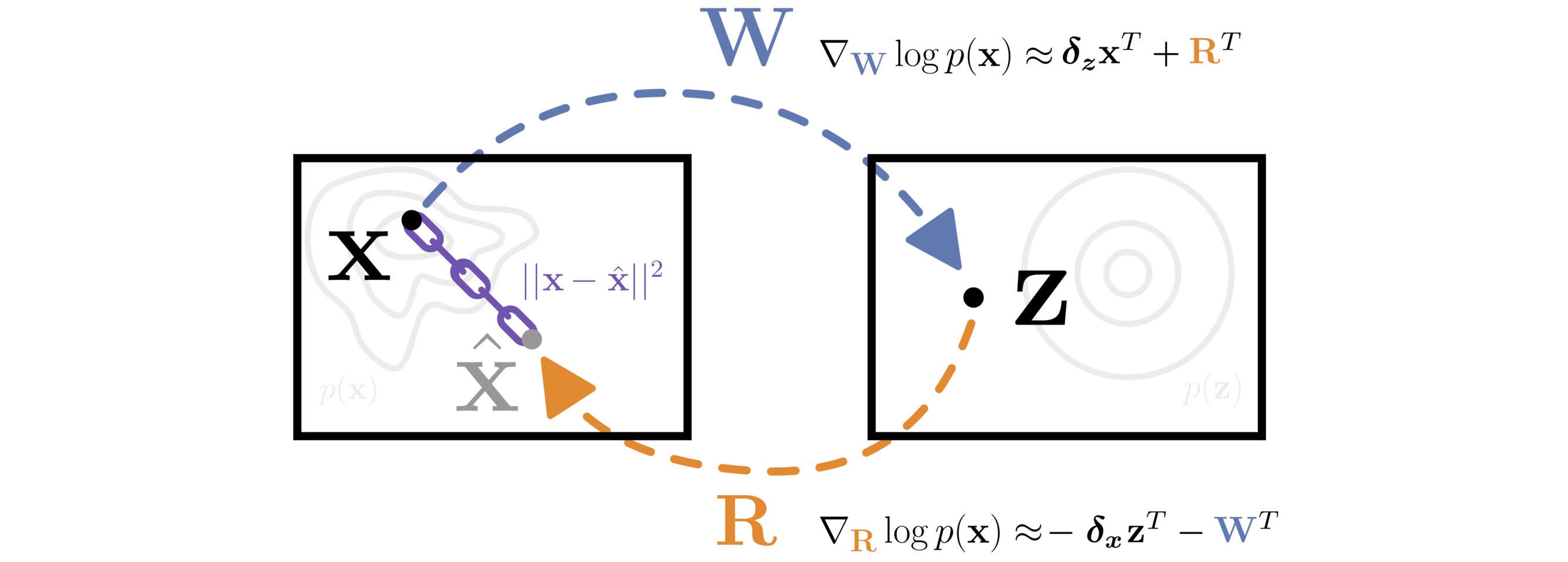 A matrix \(\mathbf{W}\) transforms data from \(\mathbf{X}\) to \(\mathbf{Z}\) space. The matrix \(\mathbf{R}\) is constrained to approximate the inverse of \(\mathbf{W}\) with a reconstruction loss \(||\mathbf{x} - \mathbf{\hat{x}}||^2\). The likelihood of the data is efficiently optimized with respect to both \(\mathbf{W}\) and \(\mathbf{R}\) by approximating the gradient of the log Jacobian determinant with the learned inverse.
A matrix \(\mathbf{W}\) transforms data from \(\mathbf{X}\) to \(\mathbf{Z}\) space. The matrix \(\mathbf{R}\) is constrained to approximate the inverse of \(\mathbf{W}\) with a reconstruction loss \(||\mathbf{x} - \mathbf{\hat{x}}||^2\). The likelihood of the data is efficiently optimized with respect to both \(\mathbf{W}\) and \(\mathbf{R}\) by approximating the gradient of the log Jacobian determinant with the learned inverse.